Edge gateway is about providing real-time decision making at the edge. In this article, I will talk about how to apply computer vision at the edge for various security and surveillance activities. For instance, you would like to detect suspicious activities at the ATM, simple cases like people wearing helmets and entering the ATM to unusual movements or would like to capture and identify objects in remote areas using Drones like crops length to mining activities. In such scenario, you would need real-time decision making at the edge as it might not make sense to transfer the data over the cloud for processing, be it for latency issues, bandwidth, cost issues or there might be none or very limited connectivity. In this case you employ intelligence at the edge of the devices.
 In order to build out the solution, you need to employ computer vision algorithms on the edge. You can build this using commercial available API’s or using various open source deep learning framework like Theano, TensorFlow, Café etc. Deep learning is a branch of machine learning for learning multiple levels of representation through neural networks. Neural network in image processing, automatically infer rules for recognizing images instead of you extracting thousands of features to detect images.
In order to build out the solution, you need to employ computer vision algorithms on the edge. You can build this using commercial available API’s or using various open source deep learning framework like Theano, TensorFlow, Café etc. Deep learning is a branch of machine learning for learning multiple levels of representation through neural networks. Neural network in image processing, automatically infer rules for recognizing images instead of you extracting thousands of features to detect images.
Various deep learning architectures are available like convolutional neural network, recurring neural network to solve specific problems like computer vision, natural language processing, speech recognition and achieves state of the art results.
For Computer Vision, we specially use a CNN network to identify images or use of the pre-trained instance (like Inception model released by Google which is a 22 layers’ deep network which achieves start of the art results for classification and detection for images). For a computer, images are nothing but a vector or set of numbers/pixels. Convolutional Neural Networks learns features automatically using small frames of equal size images and each network gets the same input and interesting pieces are extracted (for more details, please refer to how CNN works). The extract of interesting pieces (which are again vector of numbers) is the heart of how CNN works. For instance, in case of helmet, some network would learn a round edge, some may learn a glass pane in the front and so on. The idea is irrespective of where the object is in the frame, you should be able to identify to image.
Prior to CNN for image detection, you would need to crop the images and provide area of interest. For instance, if you are detecting various categories of birds, you would usually crop the bird image and remove any surrounding context, like trees, bushes, sea, sky etc and provide the bird image only. With CNN, the idea is to train with those images and let network figure this out (though cropping may help in some cases for increasing accuracy). Based on my experiments, the CNN is able to predict object most of the times which have surrounding context, but with lower accuracy. As mentioned, the idea is to identify objects irrespective of where they are found in the image and I am sure lot of research is going on to improve the CNN networks. Having the right training data (images and label) is a must for training networks with such variations.
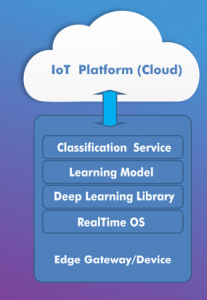
On the left hand side, is the stack view of employing deep learning API on the edge gateway. It consists of API, the learning model and the classification service which is used for classification of objects. There are lot of innovations happening to optimize the use of deep learning libraries on the edge.
So how do you go about implementing this. I will talk about one approach of building this out –
- Build your own CNN or Start with a pertained CNN network (like an Inception Model)
- Get the training and test data (images and labels)
- Train or retrain (i.e transfer learning) the network.
- Optimize with learning rates, batch size etc. for desired accuracy. Get the trained model
- Use the trained model for classification.
- Deploy TensorFlow API and trained model on the edge (you can package this in docker)
- Use the classification code on the edge gateway to detect objects.
The following is part of my presentation that I delivered at IoTNext. I will update the article with the youtube video once available.





{kind=link}