




The release of ChatGPT and the responses it provided brought back the Conversation AI to the forefront and made Conversation AI available to everyone through a simple web interface. We saw many creative ways to use ChatGPT and how it might impact the future and questions around whether it will replace the Google Search engine and Jobs.
Well, let’s address this question with the below analysis –
From early Watson systems to ChatGPT, a fundamental issue still remains with Conversational AI.
Lack of Domain Intelligence.
While ChatGPT definitely advances in the field of Conversational AI, I like to call out the following from my book- Real AI: Chatbots (published in 2019)
“AI can learn but can’t think“.
Thinking would always be left to humans on how to use the output of an AI system. AI systems and their knowledge will always be boxed to what it has learned but can never be generalized (like humans) where domain expertise and intelligence are required.
What is an example of Domain Intelligence?
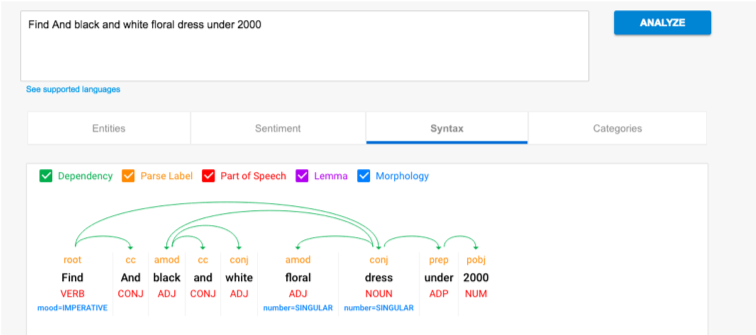
Take a simple example where you ask the Conversational AI agent to “Suggest outfits for Shorts and Saree”.
Fundamentally, any skilled person would treat them as two different options – matching outfits with Shorts and matching outfits with Saree OR asking clarifying questions, OR suggesting these options are disjoint and can’t be combined.
But with ChatGPT (or any general-purpose Conversational AI), the response was as shown below. Clearly, without understanding the domain and context, trying to fill in some responses. This is a very simple example, but the complexity grows exponentially, for deep expertise and correlation are required -like a doctor recommending options for treatment. This is the precise reason why we saw many failures when AI agents were used in solving Health problems. They tried to train general-purpose AI rather than building domain-expert AI systems.

The other issue with this Generative Dialog AI system is –
Explainability – Making the AI output explainable on how it arrived. I have described this in my earlier blog – Responsible And Ethical AI
Trust and Recommendation Bias – Rght recommendation and adaptability. I have explained this in my earlier blog. – https://navveenbalani.dev/index.php/views-opinions/its-time-to-reset-the-ai-application/
For more details, I have explained this concept in my short ebook – Real AI: Chatbots (2019) – https://amzn.to/3CmoexC
You can find the book online on my website – https://cloudsolutions.academy/how-to/ai-chatbots/ or enroll for a free video course at https://learn.cloudsolutions.academy/courses/ai-chatbots-and-limitations/
The intent of this blog was to bring awareness on ChatGPT and its current limitations. Any Technology usually has a set of limitations, and understanding these limitations will help you design and develop solutions keeping these limitations in mind.
ChatGPT definitely advances Conversation AI, and a lot of time and effort would have gone into building this. Kudos to the team behind this. Will be interesting to see how future versions of ChatGPT can address the above limitations.
In my view, ChatGPT and other AI chatbots to follow will be similar to any other tool to assist you with the required information, and you will use your thinking and intelligence to get work done.
So, sit back and relax; the current version of ChatGPT will not replace anything which requires thinking and expertise !!.
On a lighter note, this blog is not written by ChatGPT 🙂






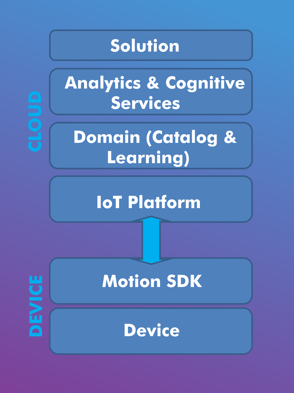
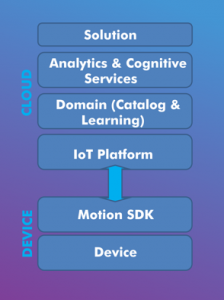 For an architecture stack perspective, you have the low powered embedded device installed inside the ball or embedded as part of the design and manufacturing process, its provides at least 6 Axis combo sensor for accelerometer and gyroscopes reading to identify any movement in 3d space. A Motion SDK is installed on top of the device to identify any movements in general and communicate the reading to the cloud. In cloud, we have the learning model or the training data. Basically, we would ask an expert batsman to bat and play various expert strokes like cover drive etc. and record their movements from sensors (bats/pads etc) as well as visuals (postures etc), this would be used as the training / test data and comparison would be made against it. As we are comparing 3D models, machine learning approaches like dimension reduction can be employed ( and many new innovation approaches) to compare two motion and predict the similarity. Similar training data is captured from an expert baller, along with other conceptual information like hand movements, pitch angles etc.
For an architecture stack perspective, you have the low powered embedded device installed inside the ball or embedded as part of the design and manufacturing process, its provides at least 6 Axis combo sensor for accelerometer and gyroscopes reading to identify any movement in 3d space. A Motion SDK is installed on top of the device to identify any movements in general and communicate the reading to the cloud. In cloud, we have the learning model or the training data. Basically, we would ask an expert batsman to bat and play various expert strokes like cover drive etc. and record their movements from sensors (bats/pads etc) as well as visuals (postures etc), this would be used as the training / test data and comparison would be made against it. As we are comparing 3D models, machine learning approaches like dimension reduction can be employed ( and many new innovation approaches) to compare two motion and predict the similarity. Similar training data is captured from an expert baller, along with other conceptual information like hand movements, pitch angles etc.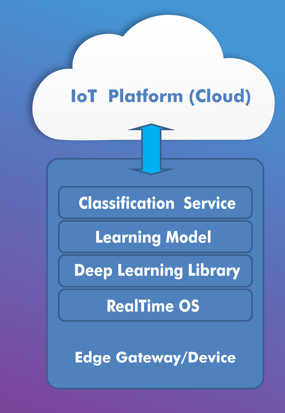
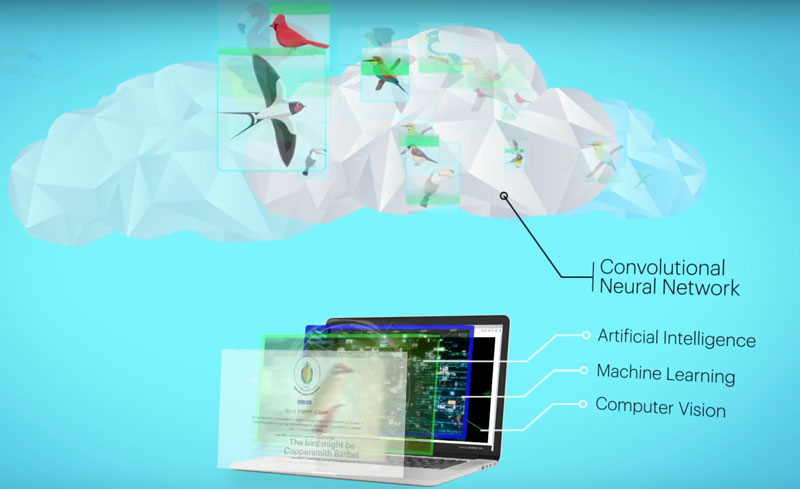
 In order to build out the solution, you need to employ computer vision algorithms on the edge. You can build this using commercial available API’s or using various open source deep learning framework like Theano, TensorFlow, Café etc. Deep learning is a branch of machine learning for learning multiple levels of representation through neural networks. Neural network in image processing, automatically infer rules for recognizing images instead of you extracting thousands of features to detect images.
In order to build out the solution, you need to employ computer vision algorithms on the edge. You can build this using commercial available API’s or using various open source deep learning framework like Theano, TensorFlow, Café etc. Deep learning is a branch of machine learning for learning multiple levels of representation through neural networks. Neural network in image processing, automatically infer rules for recognizing images instead of you extracting thousands of features to detect images.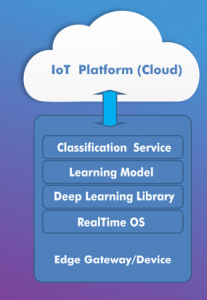
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}